

Fast, detailed, and precise, Stable Diffusion has stepped up the AI limits with its promising results.
The Stable Diffusion is a text-to-image AI diffusion model that generates unique images using advanced deep-learning methods.
It can also create videos and animations from text prompts. Stable Diffusion uses a diffusion model that turns random noise into coherent images through constant refining, giving you uniquely generated content in return!
Want to find out how it works?
In this article, we’ll break down the work process of the generative AI model, its applications, and how to access it.
Key Takeaways
-
Stable Diffusion is a generative AI model used to create images from text prompts.
-
It uses latent diffusion technology for efficient processing.
-
Stable Diffusion can be used to generate video clips and animations.
-
The generative model can be installed and run on local devices or cloud services.
-
It’s open source.
What’s Stable Diffusion
Stable Diffusion is a deep-learning AI model that generates unique images from text prompts using diffusion techniques.
The model can also generate videos, animations, inpainting, outpainting, etc. It’s built on billions of images used as training data, helping it to generate detailed, realistic images.
What’s great about Stable Diffusion is that the code and model weights are open source, giving everyone access to the model in their local hardware.
For that, you need a desktop or laptop with a GPU capable of running at least 4 GB VRAM(Video Random Access Memory).
This gives Stable Diffusion more flexibility compared to other text-to-image models that are only accessible via cloud services.
Let’s find out how it works!
How Does Stable Diffusion Work
The Stable Diffusion model works on latent space. Latent space is a multidimensional vector space, where similar items and data are grouped. It’s used in AI to compress the data and capture its underlying structure.
Running on latent space significantly reduces processing requirements. This enables the AI to run on local devices with a minimum GPU capacity of 6 GB VRAM.
This compression method saves up a lot of processing power.
So, how does it work?
Stable Diffusion uses these three main components for latent diffusion:
-
Variational Autoencoder(VAE)
-
U-Net
-
VAE Decoder
Let’s see how each component works in creating an AI image.
Variational Autoencoder(VAE)
Variation Autoencoder is a technique used to compress the image into the latent space.
The VAE consists of two components:
-
Encoder
-
Decoder
The image is compressed into the latent space using the encoder. The decoder later restores the image from its compressed form.
Using the encoder, a 512x512x3 image is converted to a 64x64x4 for the diffusion process. These small encoded images are called latents.
Increased noise is added to the latent in each state of the training.
U-Net
U-Net is the noise predictor that inputs the latent and text prompt first before predicting the denoised representation of the noisy latent.
Noise subtraction is done to get rid of the noise present in the initial latent. This generates a completely new, clean latent image.
This process is repeated a set number of times before moving the latent to the decoder.
VAE Decoder
Finally, the latent is reverted into pixel space with the decoder. This generates the final product.
And that concludes the Stable Diffusion architecture.
What Are The Uses of Stable Diffusion
Stable Diffusion showcases marked improvement over other text-to-image generation models. It requires less processing power while generating significantly better results.
So, what does Stable Diffusion do?
The answer is, “A lot of things!”
Here are some of the things you can create using Stable Diffusion:
Text-to-image Generation
Stable Diffusion excels at generating visually coherent images by translating text prompts. If you're looking to add AI image generation capability into your app, website, or any other project, consider leveraging the SDXL API.
It uses the training data to create images using adjusted seed numbers for the random generator. Different effects can be achieved by changing the denoising schedule.
Image-to-Image Generation
You can also generate new images from an existing image with a text prompt.
It can be used to add effects to the input image.
For example, I tried “A local bookstore in a suburb with a dog standing outside it” on stablediffusionweb.com and it gave me the following result:
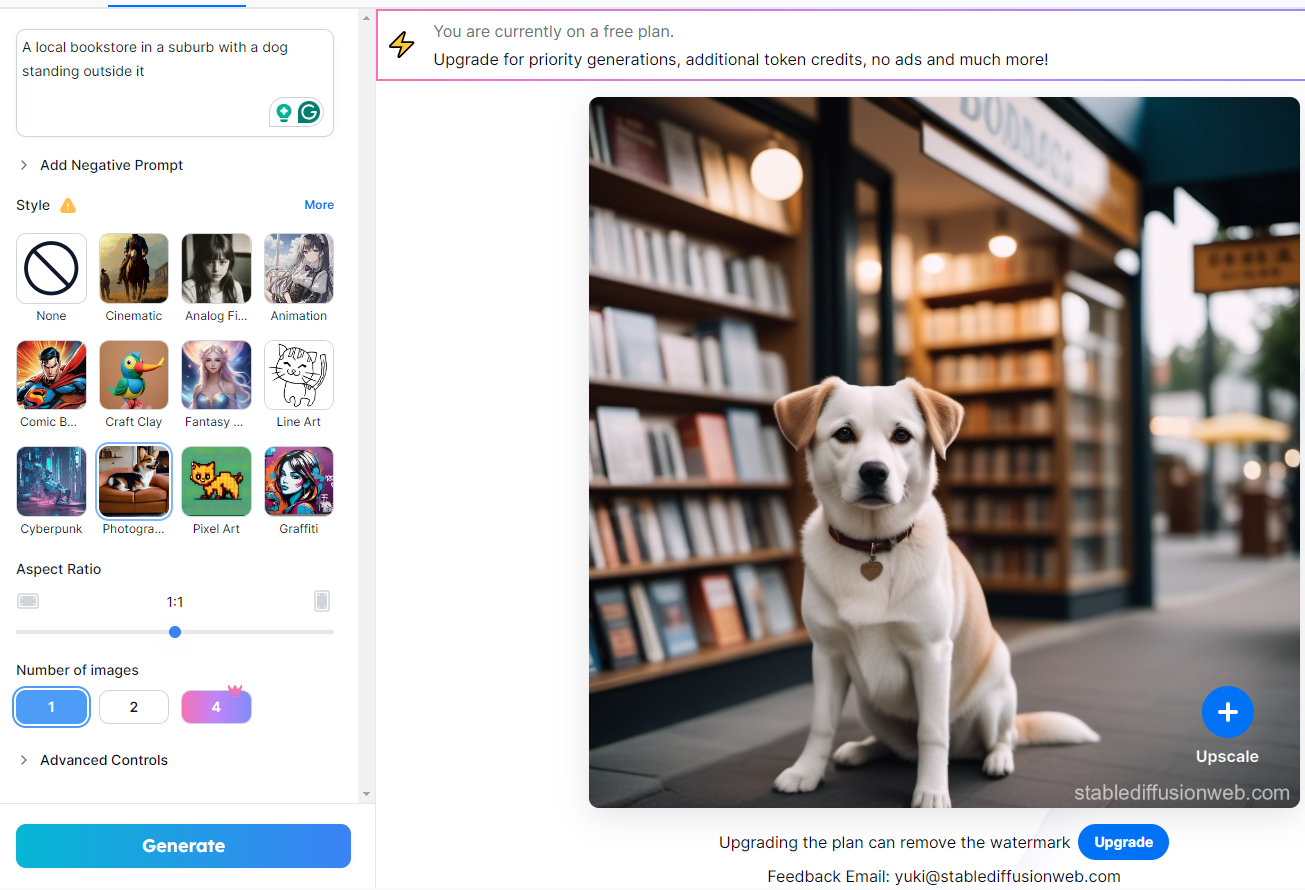
Generating Graphics, Artwork, and Logos
Stable Diffusions gives you the creative freedom to tailor your logo creation using a sketch and detailed instructions for output.
With it, you can create your artwork, designs, logos, and other content with a vast range of styles.
Inpainting
Inpainting is a process used to restore or add to specific regions of an image using image-to-image generation.
You can reconstruct any corrupted/damaged image using specific prompts.
Video creation
Stable Diffusion features like Deforum from Github can help you make short videos and animations. You can also add your preferred style to the video.
The model generates multiple images and animates them to create the impression of motion.
How To Use Stable Diffusion
So, we have learned about Stable Diffusion and its inner workings so far. But how to use Stable Diffusion?
Here are three ways to access Stable Diffusion to generate unique AI images:
-
Using Stable Diffusion Online
-
Using Cloud
-
Using Local Devices
Let’s go through them one by one.
Using Stable Diffusion Online
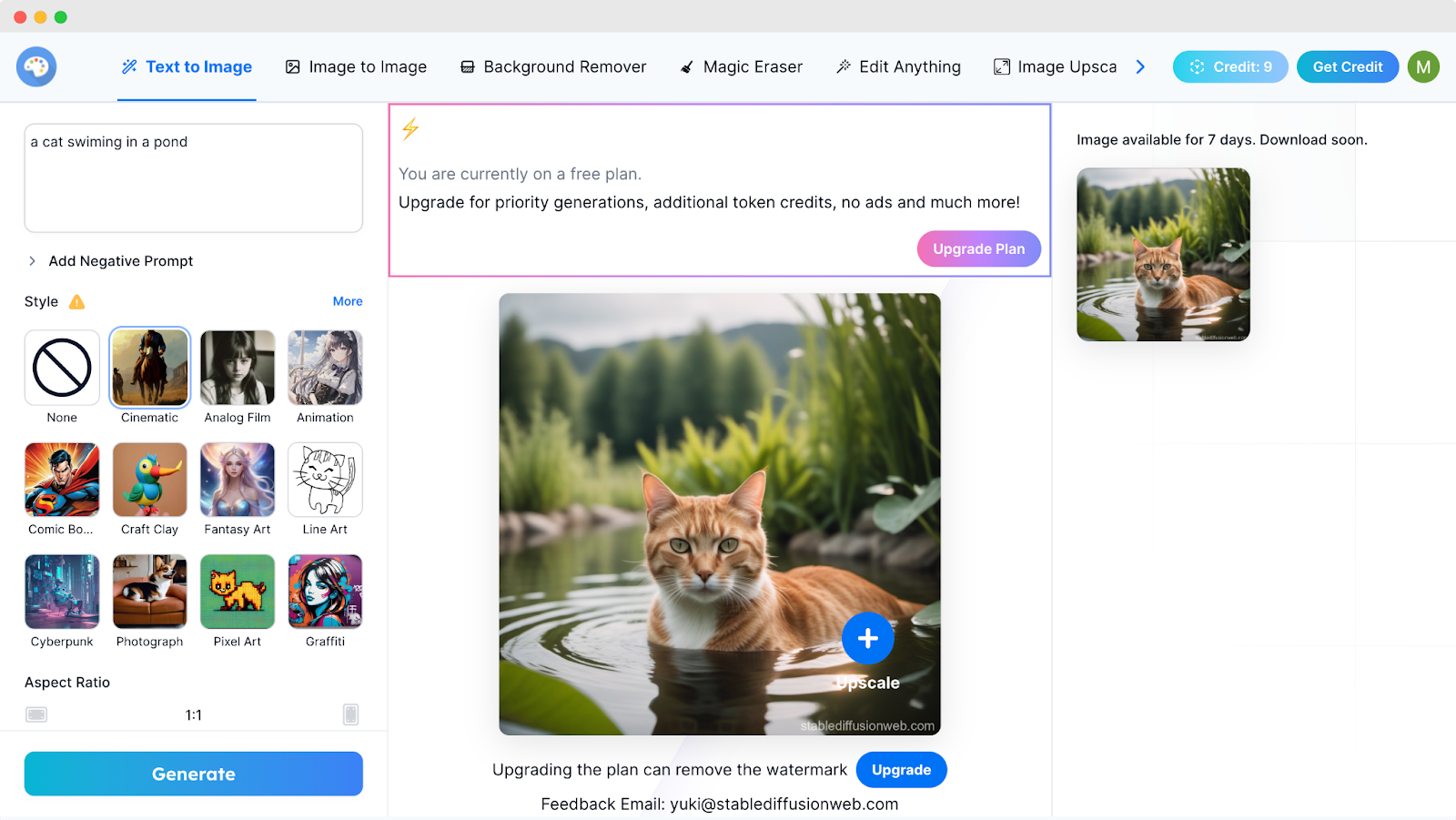
It is the easiest way to use Stable Diffusion. Follow the below steps to use the tool.
-
Visit stablediffusionweb.com and then sign up for a free account.
-
Write your prompt.
-
Select a style like Cinematic, Animation, Pixel Art, etc.
-
Define the aspect ratio and the number of images you want.
-
Hit the ‘Generate’ button.
The online platform will give you the following features:
-
Image to image
-
Text to image
-
Background remover
-
Magic Eraser
-
Image Upscaler
-
AI Clothes changer
-
AI Portrait maker
-
Sketch to image
The free version will allow you access to the basic functions. It works with a credit system that can be extended by purchasing their monthly/yearly plans. You’ll also get access to all the premium features!
So far, the cheapest plans start at $7 a month which grants access to almost all the functionalities!
Using Stable Difusion In the Cloud
This is the best and most efficient way to access Stable Diffusion. You can get access to Stable Diffusion via cloud services provided by different companies.
They also streamline the customization and prompt input features to give you a better user experience. The platform then taps into the Stable Diffusion model to generate your preferred AI art.
Using Stable Difusion Local Device
Contrary to traditional generative AI models, Stable Diffusion allows the user to install it on their local device. Thanks to their efficient processing, overcoming the limitations of most AI models. .
Many users prefer their data to be private and want to run Stable Diffusion on their devices. There are available software that facilitates the set up of Stable Diffusion on the device.
Due to being open source, Stable Diffusion is free to use on Mac and PC.
To run Stable Diffusion on your PC, your device needs to meet the minimum hardware requirements:
-
A 64-bit OS
-
At least 8 GB of RAM
-
GPU with minimum 6 GB VRAM
-
Approximately 10 GB of storage capacity
-
The Miniconda3 installer
-
GitHub files for Stable Diffusion
Local vs Cloud Installation of Stable Diffusion
Running Stable Diffusion in local devices and cloud services have their separate advantages.
Here are the core differences between using Stable Diffusion on a local device and cloud services:
| Feature | Local | Cloud |
| Cost | Requires investment for compatible hardware | Pay-as-you-go for cloud resources. |
| Hardware Requirements | Minimum 6GB VRAM GPU required | No dedicated GPU required |
| Setup | Requires manual setup, installation, and configuration | No setup or installation is required. |
| Control | Full control over the process and data. | Control relies on cloud provider limits |
| Performance | Relies on local hardware | Faster processing depending on different packages |
| Scalability | Limited to resources of the local machine | Highly scalable, and can be upgraded for access to more powerful resources. |
| Privacy | Data is private and secured in local devices. | Data is stored on the cloud provider’s servers which can be used by cloud providers. |
FAQs on What is Stable Diffusion, Answered
What Are Some Stable Diffusion Alternatives?
RunDiffusion, Midjourney, Dall-E, and Craiyon are some powerful Stable Diffusion alternatives.
Can Stable Diffusion run on a CPU?
Yes, Stable Diffusion can run on a CPU. But it won’t be as fast as a GPU-processed result. Depending on the processing speed of the CPU and the image size, it can take several minutes to generate a result with Stable Diffusion.
Can you install Stable Diffusion on Mobile?
You can’t install and run Stable Diffusion on mobile. Stable Diffusion requires a GPU with a minimum of 6 gigabytes of VRAM, which is impossible to achieve in mobiles.
Final Words
So, why should you use Stable Diffusion?
The Stable Difusion model is freely available thanks to a number of third-party interfaces. It also allows you to run the model on your local machine.
It has a growing community engaged in experimentation and development of the model. The open-source nature of the model allows more freedom and engagement from the users.
Stable Diffusion is still in its early stage and evolving gradually. We can only expect big things from the model in the coming days.
